

FPGA Technology
| As per the Future Market Insights, The global FPGA market size was valued at US$ 6.2 Bn in 2021 and is projected to grow at a compound annual growth rate of 7.6% reaching US$ 13.9 Bn by 2032 from US$ 6.7 Bn in 2022. |
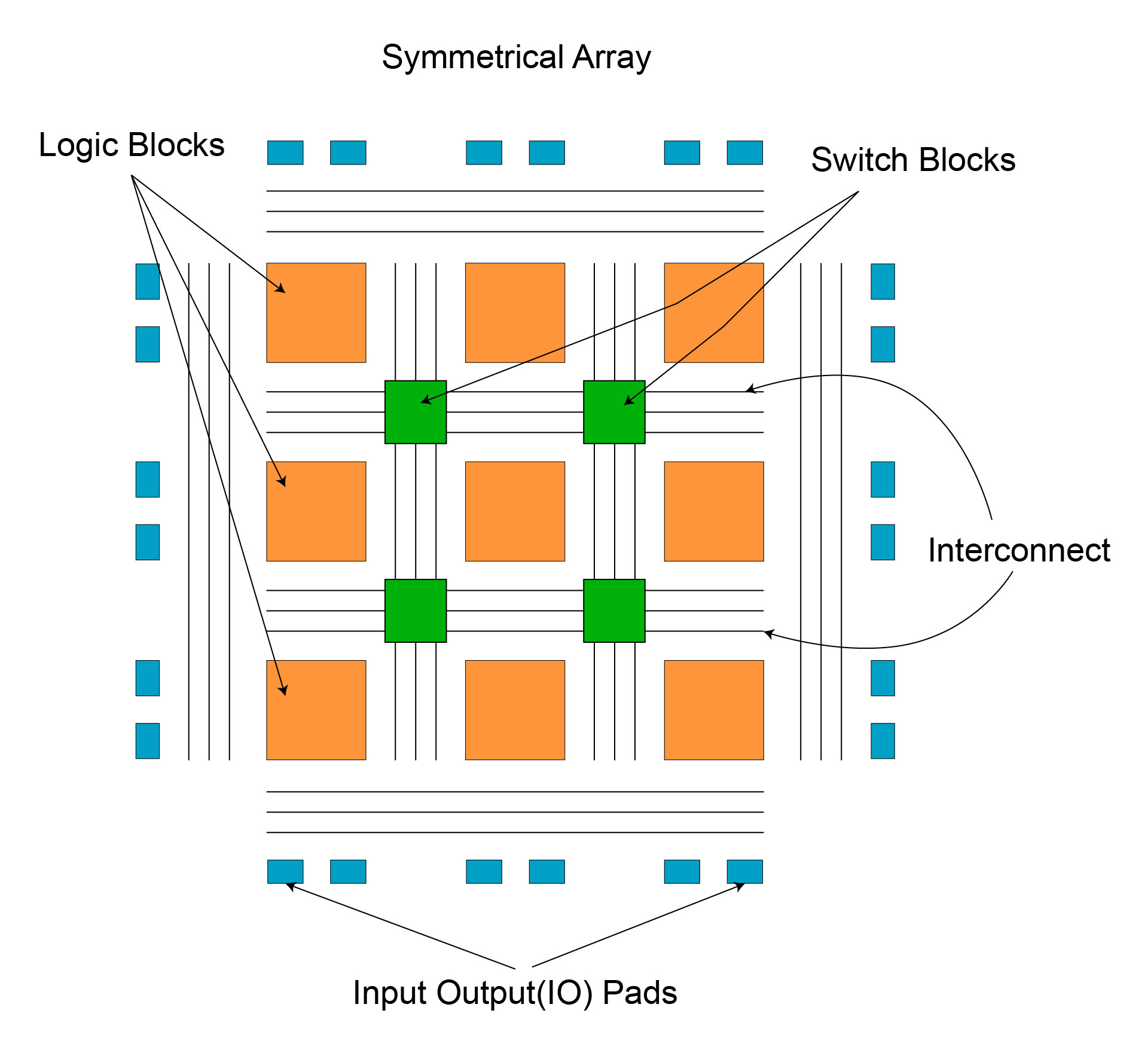
FPGAs (field-programmable gate arrays) have been around for a few decades. These devices have an array of logic blocks and a mechanism to program the blocks and their interactions, Digital Signal Processing.
An FPGA is a generic -programmable chip that can be tailored to various applications. FPGAs, unlike traditional chips, can be modified several times for varied purposes.
Developers utilize hardware description languages (HDLs) such as Verilog and VHDL to express the functionality/configuration of an FPGA.
Modern FPGAs function very similarly to application-specific integrated circuits (ASICs) when correctly reprogrammed, may meet the requirements of a specific application, much like a traditional ASIC.
FPGAs can also surpass graphics processing units (GPUs) regarding data processing acceleration.
Intel has published research comparing two generations of Intel FPGAs to an NVIDIA GPU. The experiment’s primary purpose was to see if future generations of FPGAs might compete with GPUs to accelerate AI applications.
Features, Functions, and Applications of FPGAs
Configurable logic components and memory are features of FPGA devices. A general-purpose FPGA can be set up to run and support various applications as needed.
To ensure that the FPGA is compatible with particular systems, the end-user can build various hardware designs, thanks to the modularity of FPGA designs.
The end-user or programmer can use hardware description languages like Verilog HDL, VHDL, and SystemC to implement the hardware design.
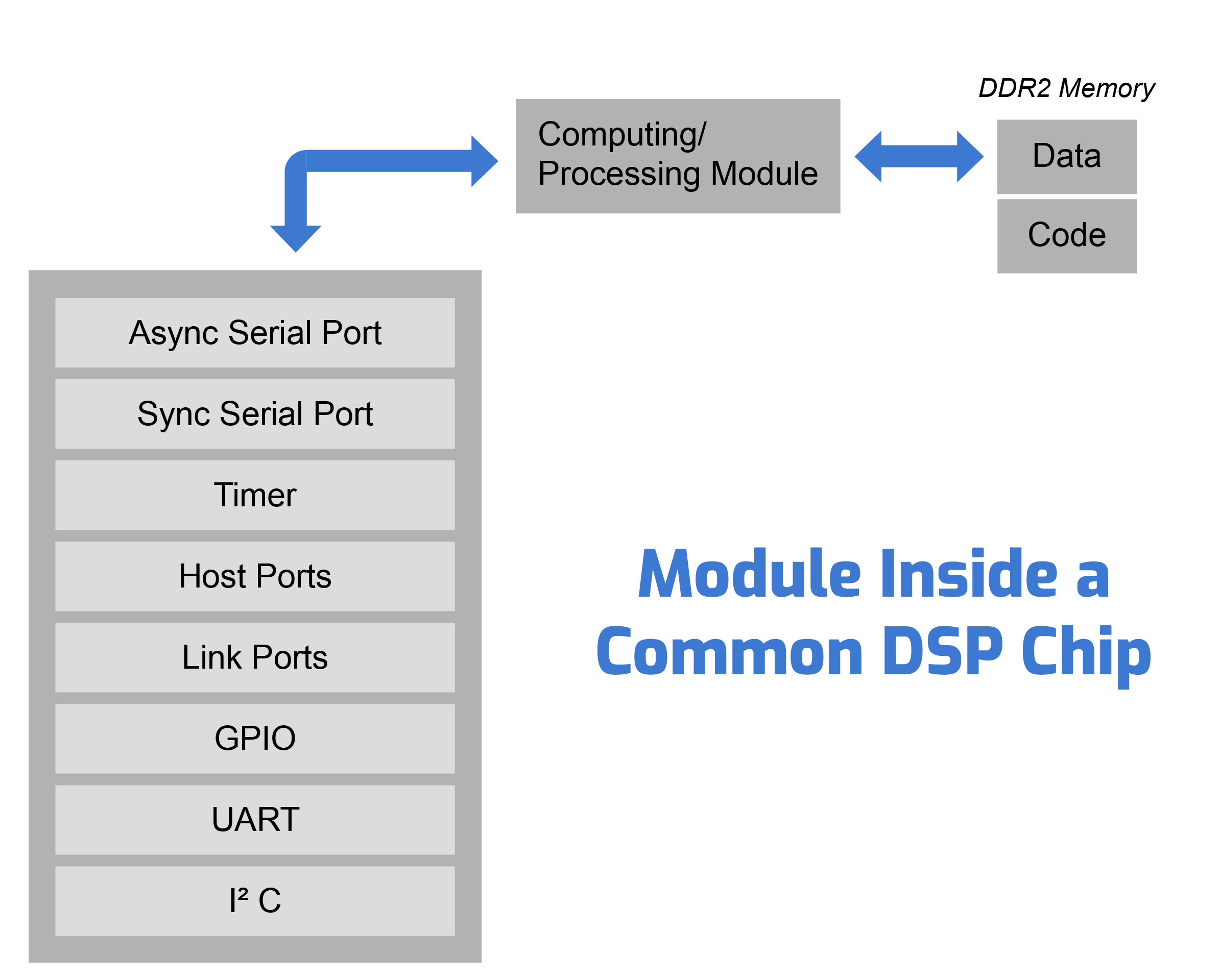
Additionally, FPGA based SoC’s come with embedded memory, ARM Cortex-M embedded processors, and DSP blocks, resulting in a standalone system designed for a particular purpose.
For instance, the necessity for external memory devices to allow the operation of an FPGA device that can manage massive data sets is removed.
Designers have the choice of implementing the system components/functions in the embedded processor or creating hardware components or implementing the functions in FPGA by utilizing its available logic resources, thanks to the flexibility of the FPGA’s design.
The typical cost of an FPGA varies depending on its functionality.
However, the most sophisticated options cost around $1,000. An FPGA is a more effective signal processing unit than conventional DSPs due to its affordability and additional capabilities, including embedded processors, memory, and hardware flexibility and configurability.
Digital Signal Processing (DSP): An Overview
| As per the survey of Future Market Insights, The global Digital Signal Processors market size is forecast to reach $18.5 billion by 2027, growing at a CAGR of 7.5% from 2022 to 2027. |
The process of evaluating and changing a signal to enhance or increase its efficiency or performance is known as digital signal processing (DSP).
It entails using various mathematical and computational techniques for analogue and digital signals to produce a higher-quality signal than the original signal.
DSP is mainly used to identify errors and filter and compress the transmission’s analogue forms. This is a form of signal analysis executed by a digital signal processor or other equipment capable of executing DSP-specific processing algorithms.
DSP typically converts an analogue signal to a digital signal before using signal processing techniques and algorithms. For example, when applied to audio signals, DSP can help minimize noise and distortion.
Examples of DSP applications are audio signal processing, digital image processing, speech recognition, biomedicine, and other applications.
Digital Signal Processing with FPGA
The ongoing digital transformation process in all industrial sectors entails abandoning traditional methods in favour of interconnection, digitalization, and improved data management.
Although traditional digital signal processors (DSPs) are still used to analyze signals and aggregate data, hardware and technology limits imply that Digital Signal Processing must be more agile to perform well in current facilities and systems.
As a result, a slew of more sophisticated signal processing solutions are required, and the field-programmable gate array (FPGA) comes into this category.
A more in-depth examination of the limits of standard Digital Signal Processing is required to better comprehend the need for adaptable signal-processing techniques. The time-consuming programming procedure for DSP software is sometimes cited as a barrier.
However, the primary issue with traditional DSPs is the rigidity of their architecture. The hardware architecture of DSP processors is notoriously rigid.
This is where Field Programmable Gate Arrays for digital signal processing have become relevant in the field of artificial intelligence and have an advantage over GPUs and ASICs.
1. Latency:
Compared to GPUs or CPUs, digital signal processing using Field Programmable gate arrays (FPGA DSP) offers a reduced latency. Since they operate in a bare-metal environment without an OS, FPGAs and ASICs are quicker than GPUs and CPUs.
2. Power:
Another area where digital signal processing using field programmable gate arrays outperforms GPUs (and CPUs) is applications with a limited power envelope. Running an app on a bare metal FPGA architecture consumes less power.
3. Flexibility: FPGAs vs ASICs:
A 12- to 18-month production cycle is typical for AI-ASICs. ASIC design changes take substantially longer to implement, whereas FPGA design changes need reprogramming, which can take anywhere from a few hours to several weeks.
Although field programmable gate arrays are notoriously challenging to programme, they have the advantages of reconfigurability and faster cycle times.
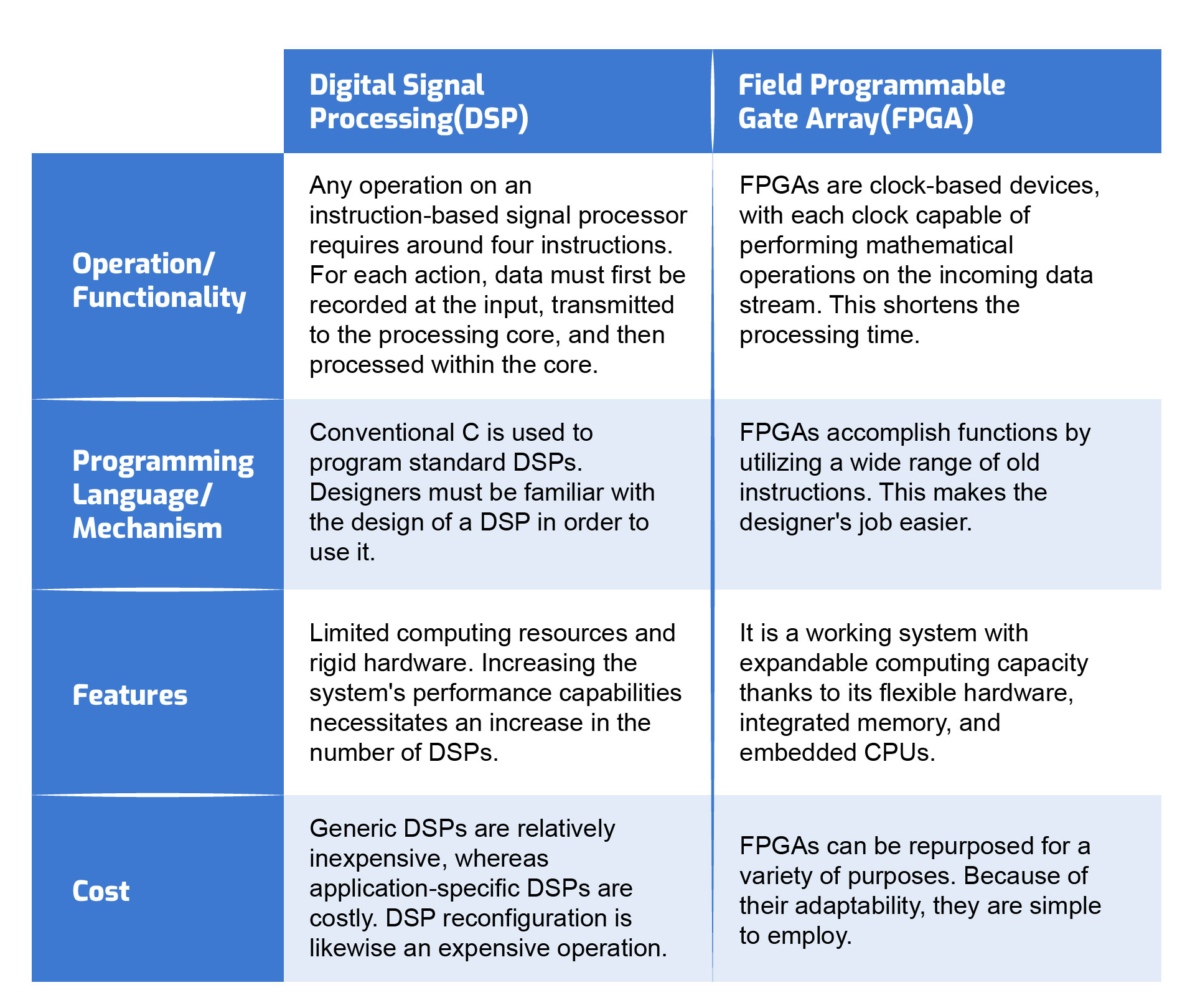
Difference between DSP and FPGA
AI Accelerator
| The global artificial intelligence market was valued at USD 93.5 billion in 2021 and is projected to expand at a compound annual growth rate (CAGR) of 38.1% from 2022 to 2030. |
An artificial intelligence (AI) accelerator is a piece of computer hardware specifically designed to meet AI requirements. It accelerates activities like artificial neural networks (ANN), machine learning (ML), and machine vision.
An AI accelerator is a high-performance parallel processing machine optimised for efficiently processing AI workloads like neural networks.
Traditionally, computer scientists focused on inventing algorithmic approaches tailored to individual problems and implemented in a high-level procedural language.
FPGA-based Acceleration as a Service
FPGA-based systems can analyse data and perform complex tasks faster than virtualised counterparts.
While not everyone can reprogram an FPGA for a specific purpose, cloud services bring FPGA-based data processing services closer to users.
Some cloud providers are even providing a new service called Acceleration as a Service (AaaS), allowing users to utilize FPGA accelerators.
When using AaaS, you can leverage FPGAs to accelerate multiple workloads, including:
- Training machine learning models
- Processing big data.
- Video streaming analytics.
- Running financial computations.
- Accelerating databases.
Some FPGA manufacturers are already developing cloud-based FPGAs for AI workload acceleration and other high-performance computing applications.
The Acceleration Stack for Intel Xeon CPU with FPGAs, also offered to Alibaba Cloud customers, includes two popular software development flows, RTL and OpenCL.
Microsoft is another large corporation that has entered the battle to develop an effective AI platform.
Their Brainwave project provides FPGA technology for accelerating deep neural network inference. They, like Alibaba Cloud, use Intel’s Stratix 10 FPGA.
While Intel leads the FPGA industry in the AI application acceleration space, Xilinx, another prominent FPGA maker, plans to enter the fray.
Xilinx has unveiled a new SDAccel integrated development environment designed to help FPGA developers collaborate with various cloud platforms.
Recent Developments in FPGA based AI
Field programmable gate arrays for digital signal processing have historically required more learning time to implement than conventional programming techniques.
When it comes to offloading the algorithms to FPGA, this has been the main bottleneck. The gap between moving the standard AI algorithms to an FPGA or FPGA-SOC specialised implementation is bridged by top FPGA manufactures’ products on AI accelerator HW platform and software development suites.
1. Xilinx ML Suite:
The Xilinx ML Suite gives programmers the ability to install and optimise rapid ML inference. It offers support for many popular machine learning frameworks, including Python and RESTful APIs as well as Caffe, MxNet, and Tensor flow.
The xDNN generic inference processor is also a feature of the Xilinx. The high-speed, power-efficient xDNN processing engine, which uses Xilinx Alveo Data Center accelerator cards, outperforms many popular CPU and GPU platforms at the moment in terms of raw performance and power economy for real-time inference workloads.
A CNN engine that supports a wide range of common CNN networks is the xDNN inference processor.
Through the Xilinx xfDNN software stack, the xDNN engine may be integrated into well-known ML frameworks like Caffe, MxNet, and TensorFlow.
A complete platform for developing AI inference, Vitis™ AI runs on Xilinx boards, devices, and Alveo™ data center acceleration cards. It includes a comprehensive collection of AI models, optimized deep-learning processing unit (DPU) cores, tools, libraries, and sample architectures for AI on edge and data center ends. Its excellent efficiency and simplicity of usage enable it to fully realize the AI acceleration potential of Xilinx FPGAs and adaptable SoCs.
2. Intel AI toolkit:
An Intel AI HW engine, including FPGAs, now supports the efficient execution of neural network models from a variety of deep learning training frameworks.
With the help of Intel’s free Open Visual Inference & Neural Network Optimisation (OpenVINO™) toolbox, a TensorFlow™, MXNet, or Caffe model may be optimised and converted for usage with any of Intel’s common HW targets and accelerators.
By converting with OpenVINO™, programmers can also run the same DNN model on a variety of Intel targets and accelerators (such as CPUs, CPUs with integrated graphics, Movidius, and Digital Signal Processing with Field Programmable Gate Arrays), experimenting to find the best fit in terms of price and performance on the actual hardware.
Accelerated AI with CPU, GPU, and DSP
1. Accelerated AI with Central Processing Unit (CPU):
With its unmatched general purpose programmability, the Intel® Xeon® Scalable CPU is the most popular server platform from the cloud to the edge for AI.
The stages of data engineering and inference make considerable use of CPUs, but training makes use of a more varied combination of GPUs and AI accelerators in addition to CPUs.
In addition, CPUs now handle packed low-precision data types and have progressively wide SIMD units, pushed by video and gaming workloads.
Because of their improved performance, CPUs are now also being employed to execute AI tasks. For sparse DNNs, small- or medium-scale parallel DNNs, and low-batch-size applications, CPUs are preferable.
2. Accelerated AI with Graphics processing units (GPU):
A GPU is a specialised semiconductor with quick processing capabilities, especially when it comes to computer graphics and image processing.
The NVIDIA Jetson device family is one illustration of technology bringing accelerated AI performance to the Edge in a power-efficient and small form factor.
For instance, the NVIDIA Jetpack SDK can be used to run neural networks on the NVIDIA Jetson Nano development board.
It includes a 128-core GPU and a quad-core ARM CPU, as well as optimised Keras and Tensor flow libraries, enabling the seamless operation and minimal setup of the majority of neural network backends and frameworks.
With the introduction of the Xe GPUs, Intel is now a player in the discrete graphics processor market.
The Intel GPU Xe is focused on efficiency while being geared for AI workloads and machine learning operations.
As a result, the various Intel GPU XE family models deliver cutting-edge performance while using less energy.
3. Accelerated AI with Digital signal processing(DSP):
Incredibly high levels of processing power are also provided by the DSPs (Digital Signal Processors) that make it possible for today’s mobile networks and ultrafast internet.
AI initially resembles digital signal processing more so than video games. DSPs and AI both take in data, process it using a number of mathematical operations, and output the results.
Although it has reached enormous performance levels, digital signal processing typically operates with far greater CPU independence than video game graphics.
As communications standards have gotten more complicated, devices are using an increasing number of DSPs that are optimised for various aspects of the standard; however, the interface between the DSPs is largely managed by the individual DSPs themselves.
To be as power-efficient as possible, the systems are typically built to function almost totally independently of the CPU.
The DSPs intend to primarily function in a pipeline, employing on-chip memory for data and to interact across DSPs for various communications stack stages, to maximise performance and decrease power consumption.
Conclusion
Technologies like artificial intelligence and machine learning are advancing quickly and require further acceleration. We are looking into a future when digital signal processing using field programmable gate arrays will be the desired alternative for creating AI applications because FPGAs from Xilinx and Intel enable toolchains for AI (ML/DL) acceleration.
Among the applications that gain from the quick deployment capabilities of any digital signal processing with field programmable gate arrays based AI systems are machine vision, autonomous driving, driver assistance, and data centers.


![Advanced Driver Assistance System [ADAS] Everything You Needs to Know](https://www.logic-fruit.com/wp-content/uploads/2022/10/Advanced-driver-assistance-systems-Thumbnail.jpg)


