

Introduction
Artificial Intelligence (AI) and Machine Learning (ML) have revolutionised the way we approach complex problems in various fields.
The success of these technologies lies in their ability to learn from data and make predictions or decisions based on that learning.
However, creating an AI or ML model is not a one-step process but a sequence of interconnected steps known as the AI/ML model workflow.
It involves data acquisition, data preprocessing, model selection, training, evaluation, and deployment.
Understanding this workflow is crucial to developing accurate and effective AI/ML models that can transform industries and improve our lives.
In this blog post, we’ll delve deeper into the AI/ML model workflow and explore each step in detail.
What is AI & ML?
Artificial Intelligence
AI (Artificial Intelligence) is a branch of computer science that focuses on creating intelligent machines that can work and learn like humans.
AI aims to create computer programs or machines that can think, reason, and make decisions as humans do.
AI encompasses various technologies, including machine learning, natural language processing, robotics, and computer vision.
Machine learning
ML (Machine Learning) is a subset of AI that focuses on enabling machines to learn and improve from experience, without being explicitly programmed.
In other words, ML algorithms enable machines to automatically learn from data, identify patterns, and make predictions or decisions based on that learning.
ML is often used in various applications, such as image recognition, speech recognition, natural language processing, recommendation systems, and predictive analytics
What is Artificial Intelligence Model Workflow?

AI workflow automation is a process that leverages artificial intelligence (AI) to launch and maintain tedious or routine tasks.
This can include projects such as data entry, processing, and analysis.
The goal of AI workflow automation is to improve efficiency and productivity by allowing computers to handle these projects instead of humans.
This can free (human) workers to focus on more complex and strategic work.
What is Machine Learning Model Workflow?

Machine learning model workflow refers to the series of steps involved in developing and deploying a machine learning model.
Machine learning model workflow is the process of developing and deploying a machine learning model, which involves a series of steps such as data preparation, model selection, training, evaluation, tuning, and deployment.
This workflow is iterative and requires continuous refinement to achieve the desired level of performance.
It is a critical aspect of building effective and efficient machine-learning models.
AI and ML model workflow

The workflow for an AI and ML model typically involves the following steps:
1. Data collection (Gathering Data)
The method of data collection depends on the kind of project we want to create; for example, if we want to create a real-time ML project, we can construct an IoT system that uses various sensor data.
The data collection may be gathered from a variety of sources, including files, databases, sensors, and many others, but it cannot be used directly for the analysis process due to the possibility of significant amounts of missing data, extremely high values, disordered text data, or noisy data.
We can also use some of the free data collections that are available online.
The most popular sources for creating machine learning models are Kaggle and UCI Machine Learning Repository.
Refer Kaggle and UCI Machine Leraning Repository here, https://www.kaggle.com/, https://archive.ics.uci.edu/ml/datasets.php

2. Data preprocessing
The act of cleaning raw data, or turning data that has been gathered from the real world into a clean data set, is known as data pre-processing.
In other words, when data is acquired from various sources, it is done so in a raw format, which makes it impossible to analyze the data.
One of the most crucial stages in machine learning is data pre-processing.
It is the most crucial stage in the process of more accurately creating machine learning models.
Types & Steps of Data Collection include,
Retrieving the data: Every day, data from databases or applications from third parties flow into businesses. Alternatively, you can use open data repositories and then gather all the data into a single repository.
Clean the data: Big data is not the same as accurate data. You must remove duplicates, fix mistakes, fill in blanks, and organize them. You must remove all false information, undesirable noise, and useless data.
Prepare the data: You must format all of the data into a model-ready format after data purification. Your data must first be divided into the train, validation, and test sets. You can identify them and combine several qualities into one if necessary.
Post the data collection and cleansing, build the datasets needed for training.
Some of the datasets you require are:
Training set: A dataset that provides the parameters necessary for the model to process input.
Validation set: For improved outcomes, check the model’s accuracy and adjust the parameters.
Test set: Used to test the model’s performance and look for any errors or incorrect training.
3. Model selection and training (Researching the model)
When a machine learning method is applied to the gathered data, the results are determined by a machine learning model. It’s crucial to pick a model that is suitable for the current job.
For various jobs like speech recognition, image recognition, prediction, etc., scientists and engineers have created a variety of models over the years.
Based on the problem definition and the data, you need to choose the most appropriate machine learning algorithm or a combination of algorithms to use for the model.
Model selection involves evaluating various models based on their performance on the problem and data at hand.
Model selection can involve various types of models such as linear regression, decision trees, support vector machines, and neural networks.

In the AI and ML model workflow, selecting the right model to address the given issue is a crucial step.
Here are some instances of model selection in AI and ML model workflow depending on the problem statement:
Image Classification: The issue statement may specify that the model must correctly categorize photos of animals when creating an image classification model. Due to their suitability for image classification tasks, models like ResNet, VGGNet, or Inception are frequently employed in this situation.
Natural Language Processing: The problem statement in natural language processing might call for a model to produce cohesive text. Since they can produce the text of excellent quality, models like GPT-3 or BERT are frequently utilized in this situation.
Regression: Regression models may be asked to predict a continuous output variable, such as the cost of a house, based on a variety of features, depending on the task at hand. Models like gradient boosting regression, random forest regression, or linear regression may be employed in this situation.
Time-Series Analysis: The issue statement in time-series analysis could ask the model to forecast future values using data from the past. Models like ARIMA, LSTM, or Prophet can be applied in this situation.
Clustering: The problem statement for clustering may demand that the model combine comparable data points. Models like hierarchical clustering or k-means can be applied in this situation.
4. Model testing and evaluation ( Training & Testing the model)
After the model has been trained, it must be tested to see how well it works on fresh, untested data. To do this, the data is divided into training and testing groups, with the testing set being used to gauge the model’s accuracy.
The validation set is used to fine-tune the model’s hyperparameters, the testing set is used to assess the model’s performance, and the training set is used to train the model.
For training a model we initially split the model into 3 three sections which are ‘Training data’, ‘Validation data’, and ‘Testing data’.
- We use a “training data set” to train the classifier, a “validation set” to fine-tune the parameters, and a “test data set” to evaluate the classifier’s performance.
- It’s vital to keep in mind that just the training and/or validation set is available when the classifier is being trained.
- The classifier’s training process must not use the test data set. Only when the classifier is being tested will the test set be accessible.
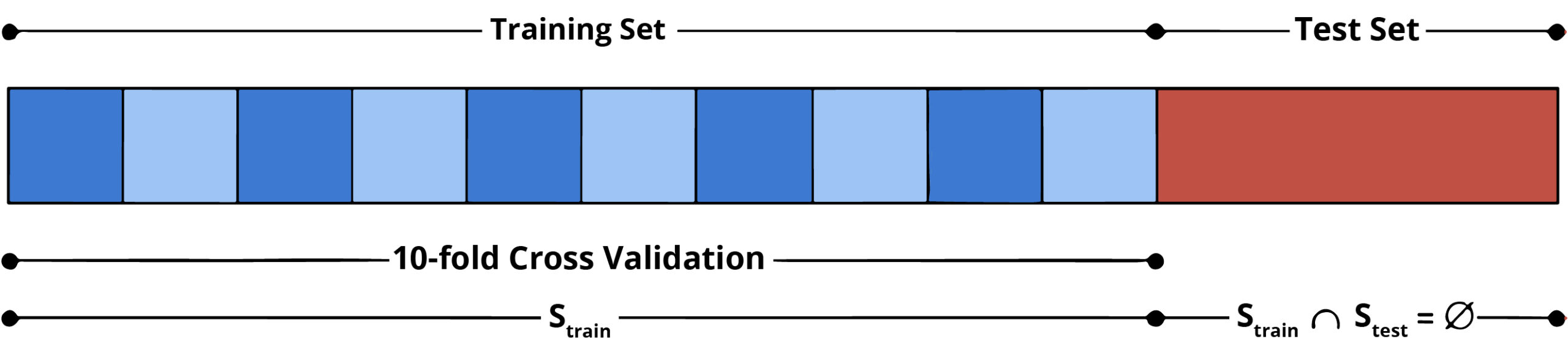
Training set: The training set is the content used to teach the computer how to process data. Algorithms are used by machine learning to carry out the training phase. To learn, or to fit the classifier’s parameters, a set of data is used.
Validation set: In applied machine learning, cross-validation is mostly used to gauge how well a machine learning model performs on untrained data. The parameters of a classifier are adjusted using a collection of unknown data from the training set.
Test set: A set of unobserved data that is exclusively used to evaluate how well a fully described classifier performs.
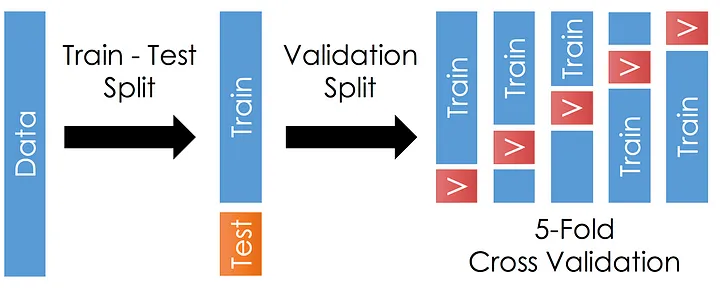
Once the data is divided into the 3 given segments we can start the training process.
A training set is used in a data set to develop a model, while a test (or validation) set is used to verify the model.
The test (validation) set does not include any of the training set’s data points. A data set is typically separated into a training set, a validation set (some people instead use “test set”), and a test set in each iteration.
It may also be divided into a training set, a validation set, and three test sets.
Once the model has been trained, we can utilize the same model to make predictions using testing data, or previously unknown data.
Once this is completed, we can create a confusion matrix, which indicates how effectively our model has been trained.
The four dimensions of a confusion matrix are “True Positives,” “True Negatives,” “False Positives,” and “False Negatives.”
To create a more accurate model, we would desire to obtain more data for the True negatives and True Positives. The number of classes has a direct impact on the Confusion matrix’s size.
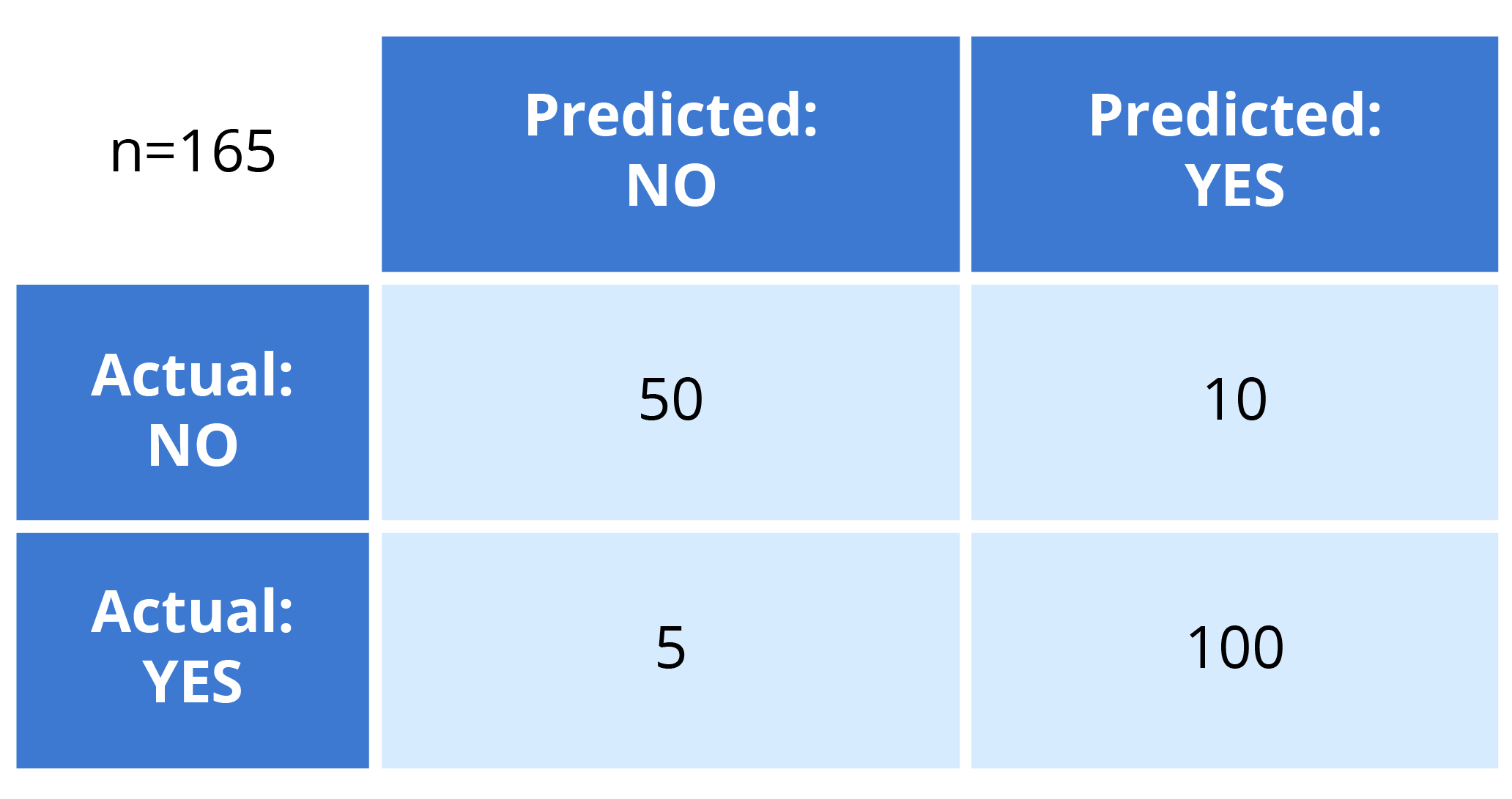
True positives: In each of these scenarios, we correctly predicted that the outcome would be TRUE.
True negatives: We predicted FALSE and our predicted output is correct.
False positives: We predicted TRUE, but the actual predicted output is FALSE.
False negatives: We predicted FALSE, but the actual predicted output is TRUE.
A variety of measures, including accuracy, precision, recall, and F1 score, can be used in the evaluation.
Accuracy
The simplest statistic, accuracy, can be calculated by dividing the total number of test cases by the number of test instances that were correctly categorized.
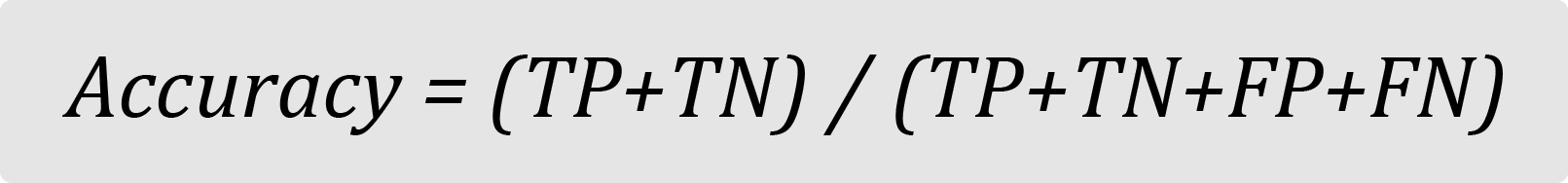
Although it may be used to solve the majority of typical issues, it is less effective when dealing with unbalanced datasets.
For instance, the ratio of fraud to non-fraud cases can be 1:99 if we are detecting fraud in bank data.
In these circumstances, the model will prove to be 99% accurate by correctly predicting that none of the test cases will include fraud. The model, which is 99% accurate, will be absolutely useless.
A model will be losing out on the 10 fraud data points if it is inadequately trained and predicts that none of 1000 (let’s say) data points are fraudulent.
If accuracy is evaluated, it will be revealed that the model accurately predicted 990 data points, making its accuracy (990/1000)*100 = 99%.
Because of this, precision is an unreliable indicator of the model’s condition.
Therefore, for such a situation, a metric is needed that may concentrate on the ten fraud data points that the model completely overlooked.
Precision
Precision is the metric used to identify the correctness of classification.
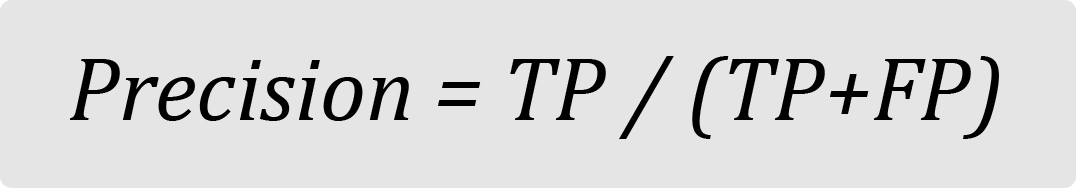
This equation, intuitively, represents the proportion of correctly classified positive events to all positively expected events. The precision increases with fraction size, improving the model’s capacity to correctly categorize the positive class.
Precision is important in the challenge of predictive maintenance, which involves foreseeing when a machine will need to be fixed.
Since maintenance is typically expensive, making wrong projections could result in a loss for the business. In these situations, it is crucial that the model correctly classifies the positive class and reduces the number of false positives.
Recall
Recall tells us the number of positive cases correctly identified out of the total number of positive cases.

Returning to the fraud issue, a high recall value will show that a lot of fraud instances were found out of the total number of frauds, which will be highly helpful in fraud cases.
F1 Score
F1 score is the harmonic mean of Recall and Precision and therefore, balances out the strengths of each.
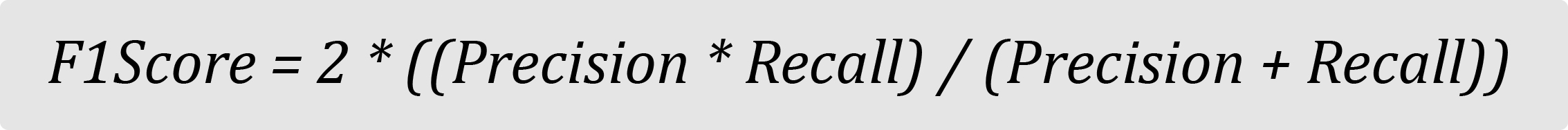
It is helpful in situations where recall and precision are both important, such as when identifying plane parts that may need repair.
Precision will be needed in this case to reduce costs for the corporation (plane parts are quite expensive), and recall will be necessary to make sure the machinery is stable and does not endanger human life.
5. Model deployment and monitoring (Evaluation)
When your model accuracy has been optimized and an acceptable collection of hyperparameters has been identified, you can test your model.
Testing is used to confirm that your models are employing accurate features by using your test dataset.
Depending on the feedback you get, you might go back and retrain the model to increase accuracy, tweak output parameters, or deploy the model as necessary.
Following the model’s deployment, it’s crucial to keep an eye on its effectiveness to make sure it keeps producing reliable forecasts.
This entails gathering information about the predictions made by the model and contrasting it with the real outcomes. For the model to maintain its accuracy and usefulness.
Challenges in AI and ML model workflow
 Data Quality and Availability: The quality and availability of data are critical to the success of AI and ML models. Data that is incomplete, inconsistent, or biased can lead to inaccurate models. Obtaining high-quality and representative data can be a challenge, especially when dealing with sensitive or proprietary information.
Data Quality and Availability: The quality and availability of data are critical to the success of AI and ML models. Data that is incomplete, inconsistent, or biased can lead to inaccurate models. Obtaining high-quality and representative data can be a challenge, especially when dealing with sensitive or proprietary information.
Example: In the healthcare industry, collecting and labeling medical images for training ML models can be challenging due to data privacy concerns and the need for expert annotation.
 Model Selection and Complexity: Choosing the most appropriate model for a given problem can be challenging, as there are many different types of algorithms available, each with its strengths and weaknesses. Additionally, complex models may be difficult to interpret and may require significant computational resources to train and evaluate.
Model Selection and Complexity: Choosing the most appropriate model for a given problem can be challenging, as there are many different types of algorithms available, each with its strengths and weaknesses. Additionally, complex models may be difficult to interpret and may require significant computational resources to train and evaluate.
Example: In the finance industry, predicting stock prices requires selecting an appropriate model, such as a Long Short-Term Memory (LSTM) network, and fine-tuning its parameters to optimize performance.
 Hyperparameter Tuning: The process of choosing the best settings for the hyperparameters in an artificial intelligence (AI) or machine learning (ML) model is known as hyperparameter tuning.
Hyperparameter Tuning: The process of choosing the best settings for the hyperparameters in an artificial intelligence (AI) or machine learning (ML) model is known as hyperparameter tuning.
The learning rate, the number of hidden layers in a neural network, or the regularization parameter in a linear regression model are examples of hyperparameters—parameters that are set before the model is trained and its behavior is established.
To get the best performance out of a model, the hyperparameters must be chosen with care. A collection of hyperparameters are chosen, the model is trained on a training dataset, its performance is assessed on a validation dataset, and the process is repeated with various sets of hyperparameters until the best-performing model is discovered.
Manual hyperparameter tuning is possible, in which the user varies each hyperparameter’s value and assesses the model’s performance.
This method, meanwhile, can be time-consuming and necessitates model and problem-domain expertise.
Alternately, automated techniques can be utilized to explore the hyperparameter space more quickly and discover the best values, such as grid search or random search.
In summary, hyperparameter tuning is a critical phase in the creation of AI and ML models. The model’s performance can be greatly enhanced and it can be better adapted to tackling the situation at hand by choosing the hyperparameters’ best values.
 Overfitting and Underfitting: In AI and ML models, overfitting and underfitting are frequent issues that arise when the model does not generalize well to new, untried data. These issues can impair the model’s performance and result in incorrect predictions or suggestions.
Overfitting and Underfitting: In AI and ML models, overfitting and underfitting are frequent issues that arise when the model does not generalize well to new, untried data. These issues can impair the model’s performance and result in incorrect predictions or suggestions.
When a model fits the training data too closely and is overfit, the model memorizes the training data rather than recognizing the underlying patterns.
Because of this, the model does well with training data but poorly with fresh, untried data.
A number of things, including utilizing too many features or too complex models, or not employing enough regularization, can lead to overfitting.
When a model is overly simplistic and unable to discern the underlying trends in the data, underfitting occurs. As a result, both the training data and fresh, unused data show low performance from the model. Utilizing too few features or too straightforward of models can result in underfitting.
A validation dataset can be used to assess the model’s performance and identify both overfitting and underfitting. The model is probably overfitting if it performs well on the training data but badly on the validation data.
The model is probably underfitting if it performs poorly on both the training and validation data.
Techniques like regularization, early halting, and model simplification can be employed to address overfitting. Early stopping halts the training process when the model’s performance on the validation data starts to deteriorate, whereas regularization adds a penalty term to the loss function to prevent the model from becoming overly complex.
Techniques like adding more features, making the model more complicated, or utilizing more sophisticated algorithms can be utilized to remedy underfitting.
 Computational Resources: Training and evaluating AI and ML models can be computationally intensive, requiring significant computing power and storage resources.
Computational Resources: Training and evaluating AI and ML models can be computationally intensive, requiring significant computing power and storage resources.
Access to high-performance computing resources can be a challenge, especially for small businesses or individual researchers.
The provision of computational resources for AI and ML models can be significantly aided by both cloud computing and graphics processing units (GPUs).
Access to computing resources like servers, storage, and networking is made available on demand via cloud computing and the Internet.
Without the need for extra hardware or infrastructure, this enables enterprises to scale their processing resources up or down as necessary. Cloud computing can be useful in a number of ways, such as:

Scalability: Depending on the demands of the AI or ML workload, cloud computing enables enterprises to scale their computational resources up or down as necessary. By doing this, businesses may be able to avoid spending money on expensive gear that might not be used to its full potential.

Cost Savings: Due to the fact that businesses only pay for the resources they actually use, cloud computing can be more affordable than conventional on-premises solutions. To further save expenses, cloud service providers frequently give rebates for prolonged use.
 Flexibility: With the help of the cloud, businesses may select the precise kind of computing resources they require, such as CPU or GPU instances, to best suit their AI or ML workloads.
Flexibility: With the help of the cloud, businesses may select the precise kind of computing resources they require, such as CPU or GPU instances, to best suit their AI or ML workloads.
AI and ML workloads are well suited for GPUs because they are specialized processors made to execute difficult mathematical calculations. GPUs can be useful in a variety of ways, including:

Speed: AI and ML models can be trained and operated more quickly thanks to GPUs because they are substantially quicker than conventional CPUs at doing mathematical operations.

Parallel Processing: GPUs can handle numerous computations at once since they are built for parallel computing. They are therefore perfect for executing extensive AI and ML workloads.

Interpretability and Explainability: As AI and ML models become more complex, it can be challenging to interpret their decisions and understand how they arrived at a particular prediction. This is particularly important in high-stakes applications such as healthcare and finance, where decisions based on AI and ML models can have significant consequences.

Ethical and Legal Considerations: The use of AI and ML models can raise ethical and legal concerns, such as privacy violations, algorithmic bias, and discrimination. Ensuring that AI and ML models are transparent, fair, and unbiased is a key challenge for the AI and ML community.
Conclusion
In conclusion, the AI and ML model workflow offers several difficulties that must be carefully considered and solved through experimentation.
The creation of precise, trustworthy, and moral AI and ML models that can be applied to resolve real-world issues depends on addressing these issues.
A variety of fascinating advancements and inventions, including AutoML and XAI as well as quantum computing and edge computing, are likely to have a significant impact on the future of AI and ML model workflows.
We can create more accurate, trustworthy, and moral AI and ML models that can be applied to a variety of real-world issues by utilizing these technologies and methods.


![Advanced Driver Assistance System [ADAS] Everything You Needs to Know](https://www.logic-fruit.com/wp-content/uploads/2022/10/Advanced-driver-assistance-systems-Thumbnail.jpg)


