

In the current era of high-performance computing, artificial intelligence, and data-intensive applications, faster and more efficient data transport between processors, accelerators, and storage devices is more crucial than ever.
PCI Express (PCIe), which enables seamless communication across a range of platforms, including consumer PCs, commercial servers, and data centers, has long been the cornerstone of this high-speed networking.
Each new generation of PCIe pushes the limits of speed, latency, and throughput, enabling engineers to build systems capable of handling unprecedented compute loads.
According to Technavio, the PCI Express market is projected to grow by USD 53.74 billion between 2023 and 2028 at a CAGR of 28.22%, driven largely by AI workloads, data center expansion, and the rising cost of computer infrastructure.
This blog offers a complete comparison of PCIe Gen 4, Gen 5, and Gen 6 focusing on data rates, architecture, signaling techniques, bandwidth, and design implications.
It also examines how these advances influence system designers, OEMs, FPGA developers, and semiconductor architects building future-ready platforms.
What is PCIe and Why It Matters
GPUs, NVMe SSDs, RAID cards, network adapters, and AI accelerators are all connected via PCI Express (PCIe), the industry-standard high-speed serial interface.
PCIe slots of different sizes- x1, x4, x8, and x16, that represent the number of lanes available for data transfer are included on every motherboard.
Two differential pairs make up each lane: one for receiving and one for broadcasting.
Because additional lanes equate to more bandwidth, PCIe can grow from simple consumer applications to sophisticated server-grade designs.
PCIe replaced the earlier shared-bus PCI architecture with a point-to-point serial protocol, simplifying system design and dramatically increasing performance.
Since its introduction, the PCIe standard has evolved consistently doubling the per-lane bandwidth with each new generation.

Evolution of PCIe Standards
Across six generations so far, PCIe has followed a simple rule:
Bandwidth per lane doubles with every generation.
This predictable scaling has enabled PCIe to remain the de facto interface for compute-intensive platforms from gaming PCs to AI supercomputers and heterogeneous data centers.

The Real Shift: PCIe as the Compute Fabric
Most discussions of PCIe focus on one thing: bandwidth doubling. But in 2025, that is no longer the real story.
Across AI, HPC, and data-intensive platforms, architects increasingly treat PCIe not as a “peripheral interconnect” but as the primary compute fabric binding GPUs, NPUs, SmartNICs, CXL memory pools, and NVMe clusters into one coherent system.
As systems scale from 2 accelerators per node to 8, 12, or even 16, the main challenges are no longer just raw throughput. They are:
- Predictable latency under load
- Deterministic behavior across many accelerators
- Error behavior and retry overhead
- Efficiency of scaling out the whole cluster
From this lens, PCIe Gen 6.0 is the first PCIe generation built for AI-native systems designed around the bottlenecks of distributed training, large-model inference, checkpointing, and memory movement at scale.
There are more than simply PHY modifications involved in the transition from NRZ to PAM4, low-latency FEC, and FLIT-based transport. They signify a shift in philosophy:
In addition to link-level speed, PCIe 6.0 is designed for system-level predictability.
This is Gen 6.0’s secret story, which explains why PCIe lanes are increasingly viewed by contemporary architectures as the foundation of the entire compute pipeline rather than just a quick slot on the motherboard.
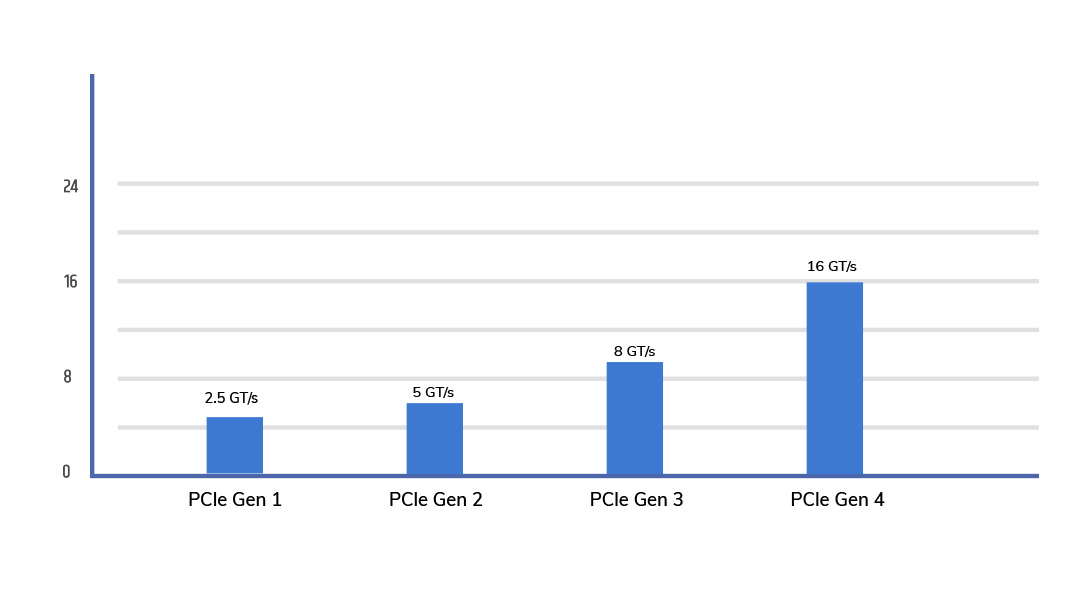
PCIe Gen 4 – The Foundation of Modern High-Speed Systems
Overview
PCIe Gen 4, announced in 2011 and standardized in 2017, delivered a major leap by doubling the bandwidth of PCIe Gen 3. It offers:
- 16 GT/s per lane
- Up to 31.5 GB/s (x16, unidirectional)
- Full backward compatibility
This generation became the backbone of high-performance desktops, enterprise servers, and early AI platforms.
Key Capabilities
- High Speed Connectivity
NVMe SSDs, GPUs, accelerators, and RAID cards with much faster load times and data processing are supported by PCIe 4.0.
- Optimization of NVMe
Ultra-low latency communication between the CPU and storage is made possible via NVMe, which makes full use of PCIe’s large bandwidth.
- Widespread Support
PCIe 4.0 is natively supported by AMD Ryzen 3000/5000, Intel 11th/12th Gen Core, and EPYC 7002/7003 CPUs.
Bandwidth and Lanes
PCIe 4.0 maintains full backward and forward compatibility. Devices utilize lane configurations (x1, x4, x8, x16) to scale bandwidth linearly.
For example:
- PCIe 3.0 x16: 16 GB/s
- PCIe 4.0 x16: 32 GB/s
- NVMe PCIe 4.0 SSDs: up to 5 GB/s read speeds
Benefits
- Increased system responsiveness and quicker load times
- Improved gaming and computationally demanding workload performance
- Reduced power consumption and energy-efficient design
- Perfect for contemporary cloud systems and data centers
Everything you need to know about PCIe 4.0
PCIe Gen 5 – Doubling Performance for AI and Data-Centric Workloads
Overview
PCIe Gen 5, finalized in 2019, doubled the bandwidth of PCIe Gen 4 to support modern AI training systems, accelerators, and high-speed networking.
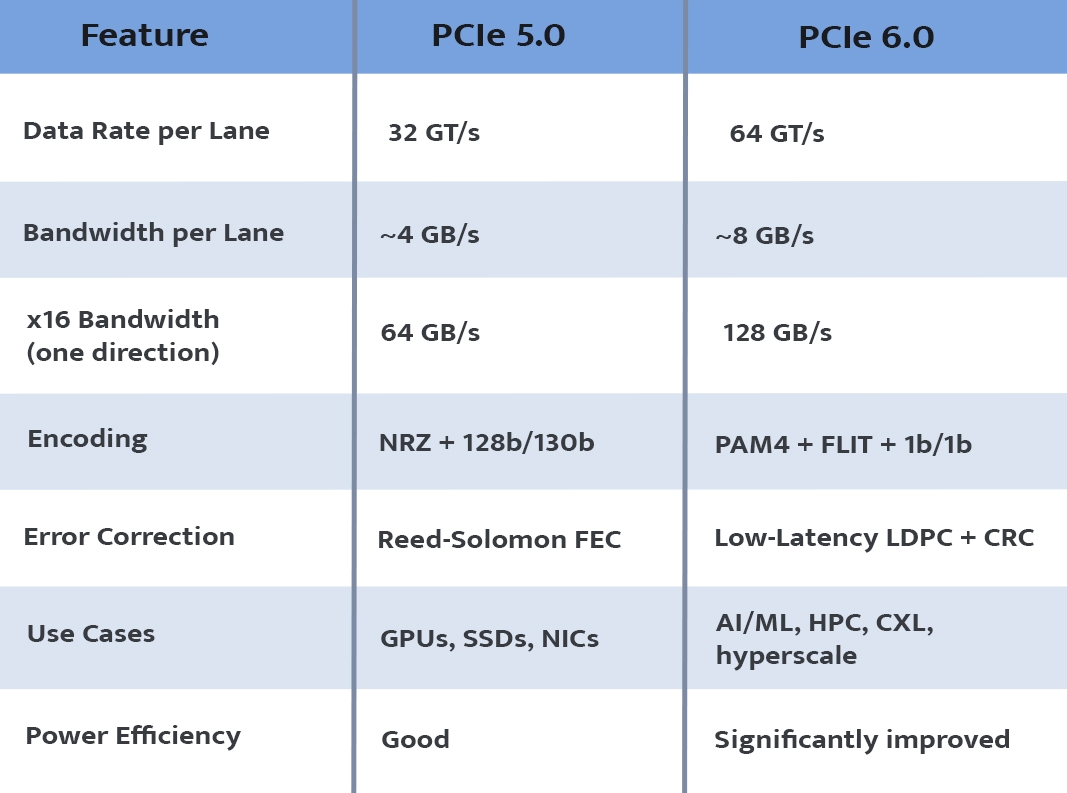
- 32 GT/s per lane
- Up to 64 GB/s (x16, unidirectional)
- Up to 128 GB/s (x16, bidirectional)
Key Improvements
- Twice the Bandwidth
Improves GPU, FPGA, storage, and NIC performance significantly.
- Support for Next-Generation Devices
PCIe 5 is used for high-speed NVMe Gen 5 SSDs, 800G Ethernet, and AI accelerators.
- Supported by Latest CPUs
Intel 12th/13th Gen Core, Xeon 4th Gen, AMD Ryzen 7000, and EPYC 9004 series.
Advantages
- Lower latency and higher throughput for AI/ML workloads
- Better performance per lane, enabling more flexible platform design
- Enhanced error correction and improved reliability
- Backward compatibility with PCIe Gen 4 and earlier

A brief comparison between PCIe 5.0 vs PCIe 4.0
PCIe Gen 6 – The Next Leap in Ultra-High-Speed Interconnects
The biggest architectural shift in PCI Express’s history occurred with the release of PCIe Gen 6 in 2021.
In order to preserve signal integrity at incredibly high rates, it introduces cutting-edge signaling technology and doubles the bandwidth of PCIe Gen 5.
Key Performance Metrics
- 64 GT/s per lane
- 128 GB/s (x16, unidirectional)
- 256 GB/s (x16, bidirectional)
- Designed for AI/ML, HPC, cloud, and data center fabrics
Where PCIe 6.0 Shines
- AI training clusters
- HPC supercomputers
- High-capacity NVMe storage arrays
- Advanced networking and 800G/1.6T Ethernet
- Data-center-scale memory expansion and CXL devices
What’s New in PCIe 6.0
PCIe 6.0 introduces several breakthroughs to achieve its massive speed increase:
1. PAM4 Signaling
Earlier PCIe versions used NRZ (1 bit per cycle).
PCIe 6 uses PAM4, which carries 2 bits per cycle, enabling higher data throughput at similar clock speeds.
![PCIe Gen 4 vs Gen 5 vs Gen 6 - A Complete Comparison of High-Speed Interconnects -blog [18]](https://www.logic-fruit.com/wp-content/uploads/2025/11/pcie-gen-4-vs-gen-5-vs-gen-6-a-complete-comparison-of-high-speed-interconnects-blog-18.jpg)
2. Forward Error Correction (FEC)
PAM4 introduces more noise and higher BER.
PCIe 6 adds low-latency FEC + CRC to maintain data integrity with minimal performance impact (<2 ns).
3. FLIT Mode
PCIe 6 uses fixed-size Flow Control Units (FLITs), improving:
- Bandwidth efficiency
- Latency
- Controller design simplicity
- Transaction throughput
This eliminates overhead from previous encoding schemes such as 128b/130b.
4. 1b/1b Encoding
Earlier generations incurred 20% (Gen1/2) or 1.5% (Gen3/4/5) overhead.
PCIe 6 reduces encoding overhead significantly with 1b/1b signaling, improving efficiency.
Field Patterns We See in Real Deployments
Across actual AI, HPC, and storage-heavy deployments, a few patterns repeat consistently:
- Gen 5 saturation happens earlier than expected when nodes host 6–8 GPUs with shared NVMe pools; most teams only discover this during late-stage scaling tests.
- Retry storms appear in mixed-use clusters (storage + compute) when NRZ links face sustained burst traffic this is where PAM4 + FEC becomes mandatory.
- Topology decisions age quickly; designs intended for “one accelerator upgrade” often hit a dead end when teams add CXL memory or extra NICs a year later.
- FLIT-mode benefits show up immediately in multi-accelerator inference setups; jitter drops even before bandwidth becomes the bottleneck.
Because of these trends, architects are beginning to see PCIe 6.0 as insurance against the predictable scale limitations they currently encounter within the first 12 to 18 months of platform growth rather than as “future speed.”
PCIe 6.0 in the Interconnect Value Stack
To understand why PCIe 6.0 feels so different from previous generations, it helps to look at it as a four-layer value stack, not just a faster PHY:
Physical Layer – PAM4 Bandwidth
- Moving from NRZ to PAM4 doubles the bits per symbol and gives architects headroom to pack more devices per node without immediately hitting a bandwidth wall.
Reliability Layer – FEC + CRC Discipline
- PAM4 inevitably raises BER. Lightweight FEC with tight latency targets turns a noisy high-speed link into a statistically reliable fabric, so large clusters can run at full speed without constantly tripping over retransmissions.
Transport Layer – FLIT-Based Flow Control
- FLITs replace variable-size packets with fixed-size units, which simplifies controllers and makes latency and throughput more predictable under diverse workloads and queue depths.
System-Orchestration Layer – Cluster-Level Scaling
- Higher bandwidth, disciplined error control, and FLIT-based transport combine to provide an interconnect that functions more like a deterministic computation fabric.
- Dense GPU, NPU, and CXL architectures can scale without collapsing due to their own complexity because of this.
In this regard, PCIe 6.0 is more about making high-density, AI-centric systems architecturally manageable than it is about achieving “twice the speed of Gen 5.”
Are you prepared to add PCIe performance that leads the industry to your system?
Download the datasheet to learn more.
PCIe 6.0 – All You Need To Know About PCIe 6.0 [2025]
PCIe 5.0 vs PCIe 6.0 – A Quick Technical Comparison
Quick Design Pressure Test: Do You Really Need Gen 6.0?
Not all systems require PCIe 6.0 right away. Architects can determine when Gen 4 or Gen 5 is sufficient and when Gen 6.0 becomes a true facilitator with the use of a straightforward “design pressure test.”
Ask three questions:
Device Density Pressure
- How many accelerators, NVMe drives, and SmartNICs must this node realistically host today and over the platform’s lifetime?
Memory Movement Pressure
- How much data has to move between host and devices, and between devices themselves (GPU↔GPU, GPU↔CXL memory, GPU↔storage) in steady state?
Latency Sensitivity Pressure
- How sensitive is the workload to jitter and tail latency does end-to-end convergence time, inference SLA, or simulation stability depend on predictable interconnect behavior?
A rough rule of thumb:
- Low pressure on all three → Gen 4 is usually sufficient.
- Medium pressure on one or two → Gen 5 is a strong “sweet spot.”
- High pressure on any one, or unpredictable load on all three → Gen 6.0 starts to pay for itself through cluster predictability and future-proofing, not just bandwidth numbers.
The detailed Gen 5 vs Gen 6 comparison below can then be read through this lens, turning it from a spec sheet into a design decision tool.
As the high-speed interconnect of the AI-driven decade, PCIe 6.0 doubles performance while enhancing efficiency, dependability, and scalability.
Practical Migration Playbook: From Gen 4/5 to Gen 6.0
Most teams won’t jump to PCIe 6.0 everywhere on day one. In practice, we see three pragmatic migration patterns that balance risk, cost, and roadmap longevity:
- Gen 4 “Stable Core” with Gen 6–Ready Design
- For existing devices, stick with PCIe Gen 4; however, design PCB stack-ups, connectors, and chassis layout so that key linkages can be upgraded to Gen 6.0 in the upcoming hardware spin without requiring a complete redesign.
- Hybrid Approach: Gen 5 Today, Gen 6 Only Where It Matters
- Use PCIe Gen 5 as the default for most slots, and reserve Gen 6.0 only for the accelerator backplane or storage fabric where density and memory movement pressure are highest. This avoids over-investing while still de-risking AI and CXL-heavy roadmaps.
- Clean-Sheet Gen 6 for AI-Native Platforms
- For brand-new AI, HPC, or disaggregated-memory platforms, start with Gen 6.0 as the primary fabric from the first design. This allows the topology, power budget, and cooling strategy to be optimized around high-density accelerators and CXL devices from day one.
The important thing is to approach PCIe 6.0 as a roadmap decision rather than a last-minute speed bump, whatever of the route you take.
The comparison table that follows is most helpful when viewed in relation to the migration pattern that your company is pursuing.
Soft-IP vs Hard-IP Considerations for PCIe 6.0
One practical issue that frequently comes up when teams are planning their PCIe 6.0 roadmaps is the decision of whether to deploy PCIe on hard IP (ASIC/SoC) or soft IP (FPGA). Different trade-offs apply to each path:
FPGA / Soft IP
- Offers faster iteration cycles, easier debugging, and more flexibility when dealing with evolving Gen 6.0 features such as PAM4 tuning, FEC behavior, or FLIT-transport optimizations.
- Reduces upfront NRE cost and allows platform teams to validate Gen 6.0 architectures before locking them into silicon.
- Total cost of ownership can be lower in early product cycles or low-to-medium volume deployments.
ASIC / Hard IP
- Provides better power efficiency, lower per-unit cost at high volume, and tighter integration for mature product lines.
- However, each design turn is expensive, and architectural corrections (e.g., new lane mappings, updated equalization settings, topology changes) are slower to incorporate once taped out.
In reality, companies assessing PCIe 6.0 frequently take a hybrid approach: after application needs and topologies are thoroughly understood.
They move a few stable subsystems to hardened silicon after validating and fine-tuning connection behavior using soft IP.
Teams can treat PCIe 6.0 as a strategic roadmap option rather than a one-time implementation choice thanks to this balanced viewpoint.
Where PCIe 6.0 Actually Changes System Behavior
PCIe 6.0 does not benefit all workloads equally. It creates the most visible impact in a few specific architecture patterns:
- Large-Scale AI Training (8+ Accelerators per Node)
- Model and data parallelism drive massive cross-device traffic. Here, PAM4 + FEC + FLIT show up as better step-time consistency and smoother scaling when moving from 4 to 8 or more accelerators.
- Latency-Sensitive Inference at Scale
- Inference farms with many accelerators and shared storage see tighter latency distribution and fewer tail events, especially when models are sharded or share CXL-attached memory pools.
- HPC and Scientific Simulation Clusters
- Workloads with fine-grained communication patterns benefit from predictable transport behavior and reduced encoding overhead, which helps maintain stability as node counts grow.
- Storage-Heavy Architectures (NVMe + CXL Memory)
- High-throughput storage backends feeding accelerators and CPUs exploit the doubled bandwidth and improved efficiency to delay expensive architectural re-designs (e.g., re-sharing storage or over-provisioning links).
Gen 4 or Gen 5 might still be the most affordable option for basic, low-density configurations single GPU nodes, moderate NVMe numbers.
However, PCIe 6.0 ceases to be a “nice-to-have speed bump” and turns into a fundamental design choice as soon as your roadmap indicates dense, AI-centric, or memory-disaggregated systems.
When PCIe 6.0 Is Overkill – Common Anti-Patterns
Despite its advantages, Gen 6.0 is not universally beneficial. A few situations consistently show no real-world gain and sometimes increased cost/complexity:
- Single-GPU or Dual-GPU Workstations: These rarely saturate Gen 4, let alone Gen 5; Gen 6.0 adds expense without measurable benefit.
- Edge Devices and Cost-Sensitive Embedded Systems: Thermal, BOM, and power budgets typically dominate; PCIe 6.0 PHY + PCB requirements can exceed practical limits.
- Low-Concurrency Storage Nodes: If you’re running only a few NVMe drives with moderate QD, the migration to Gen 6.0 yields no performance uplift.
- Clusters With Bottlenecks Elsewhere: If the limiter is CPU memory bandwidth, network fabric, or application-level parallelism, Gen 6.0 improvements do not surface.
- “Spec Sheet First” Designs: Adopting PCIe 6.0 only because it is the newest generation often leads to unnecessary architectural constraints.
The goal is not to adopt Gen 6 everywhere but to adopt it where the system-level bottlenecks justify it.
Conclusion
PCIe continues to evolve as one of the most influential interconnect standards in modern computing.
- PCIe Gen 4 laid the foundation for today’s high-performance systems.
- PCIe Gen 5 accelerated AI, storage, and networking with double the bandwidth.
- PCIe Gen 6 transforms the architecture entirely with PAM4, FLIT mode, and cutting-edge error correction delivering unprecedented bandwidth required for next-generation AI, HPC, and data center workloads.
To put it simply, PCIe Gen 6.0 became an architecture enabler, whereas PCIe Gen 4 and Gen 5 were performance enablers.
The majority of teams who still view PCIe as a peripheral bus will see “2× bandwidth on the spec sheet.”
Gen 6.0 will be used by teams who view PCIe as the computational fabric to rethink the wiring of GPUs, NPUs, CXL memory, and storage.
The Act-Now Mindset: Staying on Gen 4/5 Is Fine But Not Accidentally
PCIe Gen 6.0 does not mean that all platforms need to update right now. It does necessitate a deliberate, roadmap-driven choice.
For many products, sticking with Gen 4 or Gen 5 is completely acceptable but only if the architecture has been assessed in light of the impending demands of AI, CXL memory pooling, and fast increasing device density.
Teams will create reliable, economical systems if they purposefully postpone the implementation of Gen 6.0 and understand why.
Teams who inadvertently postpone without assessing their memory movement and topology growth paths usually incur the highest redesign expenditures in the future.
In other words:
You don’t need to adopt PCIe 6.0 everywhere today.
But you do need a PCIe 6.0 strategy today.
Understanding these generational changes is crucial for system designers, FPGA developers, and server architects to create platforms that are both robust today and prepared for future demands.




